



HDFS( Hadoop Distributed File System)是一个易于扩展的分布式文件系统,运行在网百上千台低成本的机器上。它与现有的分布式文件系统有许多相似之处,都是用来存值据的系统工具,而区别在于HDFS具有高度容错能力,旨在部署在低成本机器上。查看全文>>

对MapReduce的编程思想和模型有了了解以后,下面我们借助MapReduce编程的一个典型案例——词频统计, 来学习实现MapReduce编程开发。查看全文>>
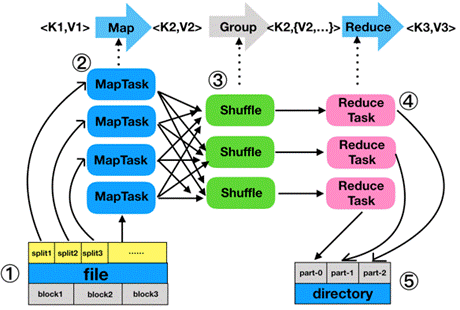
MapReduce编程模型开发简单且功能强大,专门为并行处理大规模数据量而设计,MapReduce的工作流程大致可以分为5步,具体如下:查看全文>>

以实际生产环境为背景,增加大量企业实战案例,升级MapReduce与Yarn集群性能调优,扩充HDFS数据安全与隐私保护及源码剖析、MapReduce高阶编程及Yarn核心源码剖析内容。零基础入门,帮助大家从容学习Hadoop,达到企业级使用Hadoop标准。查看全文>>

在Kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1。如果是同步模式:ack机制能够保证数据的不丢失,如果ack设置为0,风险很大,一般不建议设置为0。即使设置为1,也会随着leader宕机丢失数据。查看全文>>

Hadoop有三种运行模式:独立(本地)运行模式,伪分布式模式,和完全分布式模式。查看全文>>

















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 产品经理
产品经理 集成电路应用开发
集成电路应用开发













.jpg)